GeoWerkstatt-Projekt des Monats August 2024
Projekt: Controllable Diverse Sampling for Generative Model Based Motion Behavior Forecasting
Forschende: Yiming Xu, Hao Cheng, Monika Sester
Projektidee: The research project aims to predict multiple future possibilities of agents around autonomous vehicles in order to prevent autonomous vehicles from causing collisions when planning their own paths. This requires a large amount of data to learn a multimodal distribution through a generative model to predict multiple possible future trajectories for each agent.
Whether on foot, by bike or by car: if we want to reach our destination without an accident, we need to know the way and, above all, pay attention to what other people and vehicles we encounter are doing. We often react unconsciously, but in tricky situations our full attention is required: Does the vehicle in front of us want to turn left? Who has right of way at this junction? Autonomous vehicles also have to learn to assess and predict other road users called “agents” and their behaviour patterns. To do this, they rely on probability-based models. These models are trained with practice data containing a large number of real-life scenarios. This enables the autonomous vehicles to recognise the various possibilities of how another road user could behave in similar situations and to calculate the most likely scenario.
The models deal with so-called trajectories, the routes that the vehicles will follow over time as they navigate their environment. This trajectory encompasses not only the spatial positions but also the temporal aspects, such as speed and acceleration, at each point along the path.
There are currently two common statistical methods for predicting the trajectory of another vehicle: One is to use a regression model and train it using a winner-takes-all approach. A regression model is a statistical tool used to analyze and predict the relationship between a dependent variable and one or more independent variables. The deep learning model predicts K future trajectories and then optimizes the best one (the one closest to the ground truth). In this way, different predictions can be optimized with different data to obtain different results, thereby achieving the purpose of multimodal trajectory prediction. The other is to use a generative model to sample from the data distribution with different random seeds to obtain K different predictions. However, they are known to suffer from the risk of mode collapse and mode averaging problems when trained on a single ground-truth trajectory. - Mode collapse occurs when the generator in a Generative Adversarial Network (GAN) fails to capture the full diversity of the data distribution and instead generates a limited variety of outputs. This means that although the generator might produce high-quality samples, it does so by focusing on a narrow subset of possible outputs, neglecting other "modes" or variations in the data. Mode averaging problems can be observed in models that tend to generate outputs that are overly simplified or averaged versions of diverse data points. Instead of generating distinct samples corresponding to different modes in the data distribution, the model produces outputs that are a blend or average of these modes, leading to less realistic or less varied results. Both mode collapse and mode averaging limit a model's ability to faithfully reproduce the true distribution of the training data.
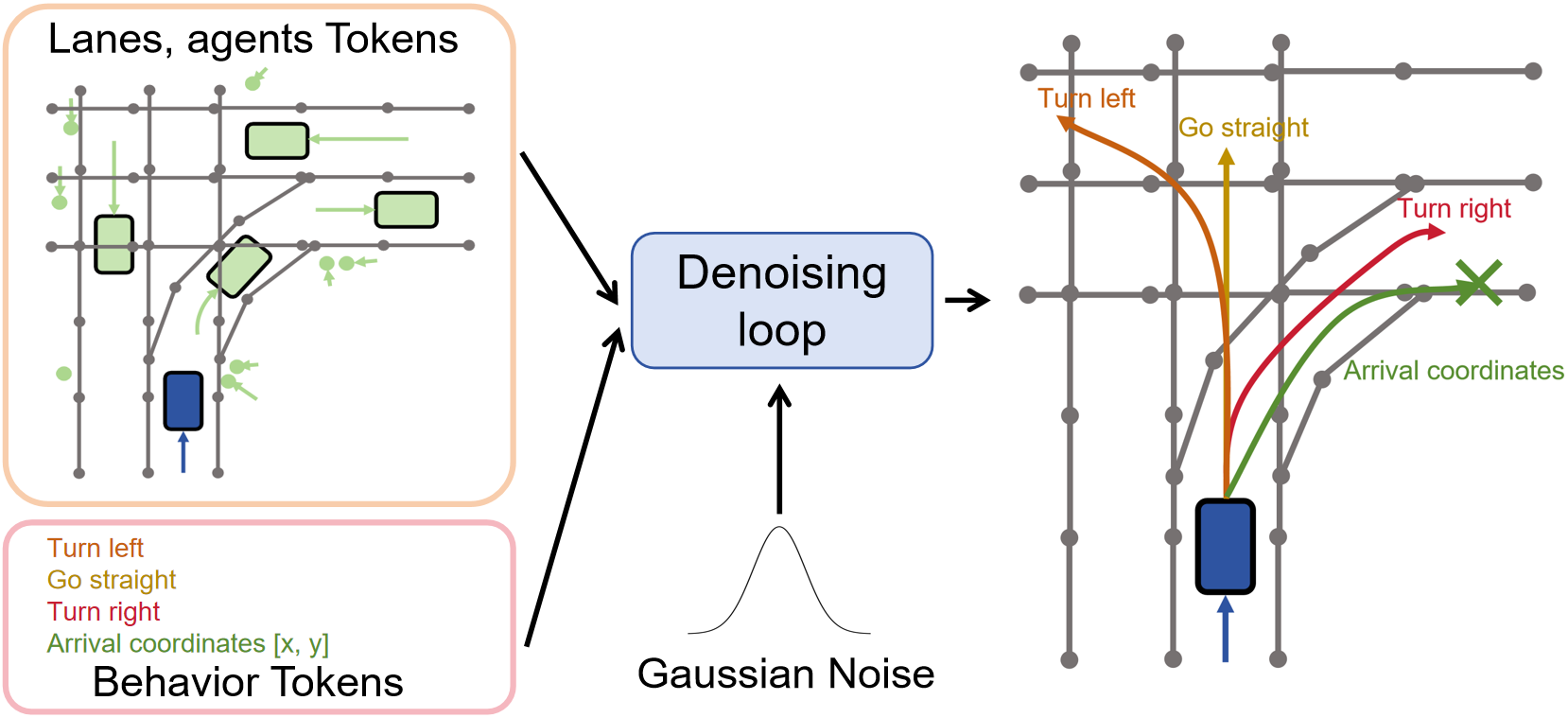
In this study we wanted to know what causes mode collapse and mode averaging problems and we found that they may be caused by very biased training data. For example, in Argoverse 1 (= public datasets to train and test methods), the data proportions for straight, left turn, and right turn are 83.6%, 10.2%, and 6.2%, respectively; Similarly, in Argoverse 2, these proportions are 81.7%, 9.5%, and 8.8%. We propose to use a controllable diffusion model for trajectory generation. This method can learn the distribution of the entire dataset. And it can be controlled by conditions to control the sampling of the desired results from the distribution. By controlling the generation of different trajectory types (such as left turn, right turn, straight ahead), we can get diverse results.
Denoising diffusion models are a class of generative models that generate new data by iteratively refining random noise through a series of diffusion-like steps., This process is like a drop of red liquid dropped into clear water. The red liquid will slowly spread throughout the water and eventually evenly dye the entire surface of the water. We can learn the reverse process of this process through a deep learning network and extract the original red liquid from the dyed water. In the context of deep learning, these denoising diffusion models are adapted for data transformation: What we do is to destroy the original information step by step, and then in the process of deep neural network learning to reconstruct information, it can learn the knowledge of the original information. We can control the generation of information during the reconstruction process. In this work, when the network reconstructs the trajectory, we can intervene in the direction and speed of trajectory generation. The figure 1 below is a schematic diagram of our method. We combine map information and control information into the denoising diffusion model to control the model to sample from pure Gaussian noise (=random noise) and obtain diverse results.
 ©
ikg
©
ikg
In our model, which we call Controllable Diffusion Trajectory (CDT), we first encode all vehicle information and map information, and then encode control information. All content is fed into the denoiser as a condition. Then the trajectory is sampled from Gaussian noise step by step. We conducted four different comparative experiments, the first is the baseline, which only uses map and vehicle information for sampling. The second is to remove the map information (CDT w/o map tokens) and only use vehicle information and control information for sampling. The third is to use all information for sampling (CDT-B). The fourth is to use the endpoint information for sampling (CDT-P). We also show the comparison with the best existing regression model QCNet. Figure 2 shows the comparison results.
 ©
ikg
©
ikg
From the results, we can draw some conclusions. 1. The Baseline model lacks diversity due to the lack of control conditions. 2. If map data is not added, the lack of lane line constraints will cause the generated trajectory to enter the non-drivable area. 3. CDT-B has the best effect, including diversity and lane line constraints. 4. CDT-P has the most accurate results. This is because the use of endpoints for prediction has strong constraints, but the diversity will be very small. 5. Compared with regression models, controllable generative models can produce higher diversity.





